「10日くらいでできる!プログラミング言語自作入門」(以下、「言語自作入門」)のインタプリタをバージョンHL-6aまで実装した感想を書いておこうと思い立ちました。
いままさに言語自作入門を読んでいる人たち・はりぼて言語の処理系を実装している人たちと、わいわいにぎやかに雑談しているような気持ちで書いてみようと思います。
2021年の春ごろ、わたしは流れてきたツイートで言語自作入門を知り、強く興味を惹かれて読みはじめました。
このときは、変数名や関数名を説明的に変更するにとどめて、C言語で写経しました。
公式処理系の実装言語がC言語だったからです。
しかし、わたしは自作言語の処理系をC言語以外でも書きたいと考えていたので、移植先の言語でうまく書くことができるのか、という課題意識をずっと持っていました。
そして2021年の年末に、Swiftではりぼて言語の処理系を書くことにチャレンジしました。
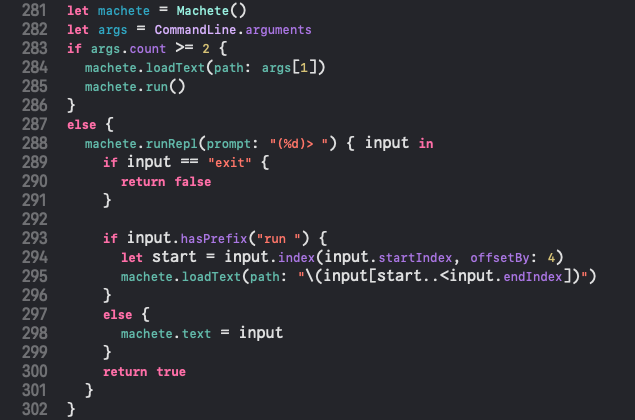
いやー、たのしかった。
なんとか目標としていたHL-6aまでは実装が終わっています。
ところで、はりぼて言語の生みの親であり言語自作入門の著者でもある川合秀実さんは、実は7章(HL-7)を推しています。
私がちょっと前から書いている「10日くらいでできる!プログラミング言語自作入門」が、7章まで書けました。
— 川合秀実 (@hkawai3) 2021年3月12日
正直、6章まででは簡単なことしかできなくて、あまりお勧めできない内容でした。しかし7章(HL-7)になって、やっと普通の人にも参考になりそうなことが書けたと思います。 pic.twitter.com/ZeT5xtAL86
そして、はじめにC言語で処理系を実装しながら読んだときは、やはりわたしも7章を特に興味深く読んだのでした。
ただ、今回Swiftで処理系を実装しながら言語自作入門の1章から6章までを読みなおしてみると、前半もしっかりおもしろかったのです。
そういうわけで、背伸びせずに、のんびりとお茶でも飲みながら感想を書いてみます。
追記・お知らせ
2023年にC言語による実装をリライトしました。
写経から改造へ踏み出す小さな一歩として、2021年に写経した実装を2023年にリライトした実装です。
注意
以下の感想文の中には、はりぼて言語の処理系がどのような処理をしているかについての記述や処理の流れを図示する箇所が含まれています。
これらは、あくまでもわたしが処理系を実装する際に一応の理解とした内容に基づいており、必ずしも公式の見解と一致するものではありません。
また、各見出のバージョン表記の横に書いたコメントは、公式サイトの「もくじ」>「説明」に書かれているコメントを引用しています。
HL-1 「初めの一歩、たった49行のシンプルすぎる言語処理系」
http://essen.osask.jp/?a21_txt01
49行です。
言語自作入門の冒頭に書かれている目的別ガイドでは「とにかく言語の本質だけが知りたければ、HL-1だけ読めばいいです。49行で処理系を理解できます」と紹介されています。
入門者でも「ちょっとやってみようかな」と気楽に始められそうですし、実際、わたしはそんなノリで読みはじめたのでした。
このバージョンには、ちょっとした制限があります。変数名を半角一文字のみ、数値定数を整数一桁のみ、命令を足し算と引き算、そしてprintのみに限定しているのです。
その代わりに、たったの49行で次のようなプログラムが実行できる処理系を実装してしまいます。
a=1; b=2; c=a+b; print c;
Output:
3
わたしのSwiftによる実装(HL-1)では、Playgroundで気楽に試せるようにソースコードをファイルから読み込むのではなくプロパティに直接書くようにしました。
var text = """ a=1; b=2; c=a+b; print c; """
Playgroundでプロパティの値をいじって出力される値を変えて遊んでいると、いつかわたしにもかっこいい言語が作れちゃうんじゃないかという妄想がふくらんでいきます。
おっと、妄想は置いておいて。
HL-1では、txt変数にソースコードの文字列を格納しておき、ソースコードの先頭からの相対位置をtxt[pc]のようにpcで指しながら命令を解析し実行する処理を繰り返します。
この処理って、いわゆるコンピュータアーキテクチャの話に出てくるあれみたいだよねとわたしは思っています。あれというのは、CPUがPC(プログラムカウンタ)の値を進めながらメモリの命令を読み込んで解釈実行する命令サイクルのことです。
はりぼて言語の公式処理系はあとのバージョン(HL-6)になると、ソースコードを内部コードへ変換してVMの上で実行するようになったり、さらに「10日くらいでできる!プログラミング言語自作入門」の続編(JITコンパイラ編)まで読み進めると、今度は内部コードの代わりに機械語に変換して実行するようになったりします。
こう書くとむずかしそうに見えるし、実際、続編で意表をついて機械語が出てきたときは、わたしもひるみました。ひるみまくりました。
しかし、細かい話・むずかしい話を除いて、はりぼて言語の公式処理系が「結局、何をしているのか」と考えると、上で触れた命令サイクルに見立てた処理でプログラムを解釈実行していると言えそうです。
その意味においては、たったの49行で書かれているHL-1の処理系はたとえまだ低機能であるとしても、すでにHL-6や続編のJITコンパイラとの共通性を有していると思うのです。わたしはそこにおもしろみを感じます。
HL-2 「変数名は1文字じゃなくてもOK、見やすいスペースやインデントもOKに」
http://essen.osask.jp/?a21_txt01_2
HL-2では、レキサー(字句解析器)を実装します。
入力されたソースコードをトークン(単語)に切り分けるのがレキサーです。
レキサーを実装して処理系がトークンを解釈できるようになると、 「変数名を半角一文字のみ」「数値定数を整数一桁のみ」とする制限がなくなり次のようなプログラムを実行できるようになります。
abc = 123; def = 456; ans = abc + def; ans = ans - 321; print ans;
Output:
258
見慣れた感じになりましたね。
はりぼて言語の公式処理系のレキサーは、トークンを切り分ける際にトークンコードを割り当てる工夫をしています。トークンコードは、トークンごとに割り当てられる整数値です。同じトークンには同じ値が割り当てられます。
これにより、プログラムを解釈する際にトークンを文字列のまま比較するのではなく、トークンコード(整数値)で比較できるようになるため処理が高速化するというわけです。
int main(int argc, const char **argv) { int pc, pc1; unsigned char txt[10000]; loadText(argc, argv, txt, 10000); pc1 = lexer(txt, tc); // これ以降のトークンの比較はすべてトークンコード(整数値)でおこなえる ...
そういえば、はじめてHL-2を読んだときは、レキサーも実装したしそろそろ構文解析のところでASTが出てくるのかなと思いました。しかし、はりぼて言語の公式処理系はASTを生成しません。
なぜこう勘違いしたかというと、言語自作入門の前に読んだ『Go言語でつくるインタプリタ』で実装した処理系が、再帰的下向き構文解析を用いて構築したASTをたどる評価戦略を採用していたからなんですね。
不勉強を反省して読み返してみると、ASTを構築しない評価戦略についてもちゃんと書かれていました(p117)。
この戦略のバリエーションには、ASTを構築しないものもある。構文解析器がASTを構築せずに直接バイトコードを出力するんだ。[…]どの戦略を選ぶかは、性能と移植性の要求、解釈しようとしているプログラミング言語、どこまでやりたいかによって大体決まる。再帰的にASTを評価するtree-walkingインタプリタはおそらく全てのアプローチの中で最も遅い。しかし、構築しやすく、拡張しやすく、考えやすく、実装に使う言語と同程度の移植性を備える。バイトコードにコンパイルし、仮想マシンを使ってそのバイトコードを評価するインタプリタは、かなり速く動作することだろう。しかし、より複雑で、実装もむずかしい。
ふむふむ、はりぼて言語の公式処理系は、「ASTを構築しない」で「バイトコードにコンパイルし、仮想マシンを使ってそのバイトコードを評価するインタプリタ」だと言えそうです。
この戦略を採用したのはおそらく作者が実行速度を重視しているためでしょう。プログラムを解析した結果を連続したメモリ領域に格納しておけば、局所性が高まりキャッシュのヒット率が上がります。
処理系の実行速度の参考として、足し算を1億回繰り返すプログラムを実行した速度をHL-6aの感想文に掲載しています。
そこでは他言語の処理系との比較はおこなっていませんが、たとえばこれと同等の処理をわたしの手元のCPython (Python 3.9.10) で実行した速度と比べてみると、Swiftによる実装でも1/17倍ほど速く、C言語による実装ではさらに1/2倍ほど速い結果となりました。
公式処理系のセキュリティに関して公式サイトの「(5) 重要な注意事項」には、「これは私の説明のための教材であって、製品や実用的な言語処理系ではありません」と書かれています。
しかし、実行速度に関してはその限りではなさそうです。改造してあんなところやこんなところで使ってみたいなぁ、なんて妄想がふくらんでいきます。
おっと、妄想は置いておいて。
HL-3 「条件分岐などをサポートしてループ処理が可能に」
http://essen.osask.jp/?a21_txt01_3
HL-3では、goto命令を追加します。
うわっ、goto命令だって? 処理が追いにくくなるから僕は使わないよ、という意見のプログラマがいる一方で、いやいや、使い方によっては便利だよ、という意見のプログラマがいます。
ただ、わたしはHL-3で追加するgoto命令について「は」、双方の意見を戦わせることはナンセンスだと考えています。
はりぼて言語の処理系を書き進めていく中で、ひとつわたしが勝手に思っていることがあって、それは、はりぼて言語の公式処理系にはあえて低水準言語のイディオムを利用して処理を実装しているところがあるのではないかということなんですね。
どういうことなのかというと、たとえばx86アセンブリには、高水準言語では提供されているifやforという制御構文がありません。
わたしがはじめてこれを知ったときは、じゃあどうやってプログラムの実行を制御するの? と思いました。
じゃあどうするかというとjump命令を使うのです。jump命令は、次に実行する命令を指しているプログラムカウンタの値を書き換える命令です。
このjump命令を使うと、高水準言語が提供する抽象度が高い制御構造と等価な処理を実装することができます。
そして実は、はりぼて言語の公式処理系はあとのバージョン(HL-8)で、まるでアセンブリのjump命令のようにgoto命令を使ってifやforという制御構造を追加するのです。
if文と、goto命令を使った等価な処理
if (条件式) {
コードブロック
}
if (!条件式) goto label;
コードブロック
label:
for文と、goto命令を使った等価な処理
for(式0; 条件式; 式2) {
コードブロック
}
式0;
if (!条件式) goto label2;
label0:
コードブロック;
label1: // continue命令が来たらここにジャンプする
式2;
if (条件式) goto label0;
label2:
わたしはHL-1の感想文で次のように書きました。
はりぼて言語の公式処理系が「結局、何をしているのか」と考えると、バージョンによって実装の詳細は違ったとしても、[…]命令サイクルに見立てた処理でプログラムを解釈実行していると言えそうです。
この「結局、何をしているのか」ということ、つまり本質は何かということを制御構造について考えると、それはjump命令だよ、だってjump命令さえあれば抽象度が高い制御構造と等価な処理を書けちゃうからね、と言えると思います。
この理解のために、あえて低水準言語のイディオムを利用して処理を実装しているのであれば、HL-3で追加するgoto命令の良し悪しについて高水準言語のパラダイムだけにもとづいて意見を戦わせてもナンセンスだよなぁ、と考えるわけです。
HL-4 「REPLの導入(これは楽しい!)」
http://essen.osask.jp/?a21_txt01_4
REPLはたのしいです!
HL-5 「少し高速化」
http://essen.osask.jp/?a21_txt01_5
HL-5では、phrCmp関数を実装します。
HL-5までのはりぼて言語の公式処理系がやっていることの流れをおおまかに図示するとこうなります。
ソースコードを入力として受け取る -> 字句解析をする -> 構文解析をしながら実行する
この図の「構文解析をしながら実行する」の構文解析をしてくれるのがphrCmp関数です。
phrCmp関数は構文を表した文字列であるフレーズを引数に取り、それを関数本体で字句解析して、その結果のトークンコード列を変数に格納しておきます。そして格納したフレーズのトークンコード列と、ソースコードを字句解析して得たトークンコード列の並びを比較して、それらが一致するかを判定します。
また、フレーズを指定する際はワイルドカードが使えます。ワイルドカードにマッチしたトークンの位置はwpcという配列に入れておいてプログラムを実行する際に使います。
この大事なお仕事をしてくれるだけでも、phrCmpさん、おつかれさま、いつもありがとう、という気持ちになるんですけども今回Swiftによる実装をしながら、ふと、ユーザ(プログラマ)が言語を改造する際のインターフェースを提供しているという意味でも大事な関数と言えるんじゃないかな、と考えました。
わたしのSwiftによる実装では、HL-4まではトークンコード列の並びが正しいかを判定する処理をこんな感じで書いていました。
let assign = getTokenCode("=") let semicolon = getTokenCode(";") ... pc = 0 while pc < nTokens { if tc[pc + 1] == assign && tc[pc + 3] == semicolon { // 単純代入 // このブロックで実行して、その結果を変数に書き込む } ...
この処理が、HL-5でphrCmpメソッドを実装するとこんな感じで書けるようになります。
pc = 0 while pc < nTokens { if phrCmp(id: 1, phrase: "!!*0 = !!*1;", beginning: pc) { // 単純代入 // このブロックで実行して、その結果を変数に書き込む } ...
さらに、わたしはextensionを使ってStringにラッパーを追加してこう書いています。
pc = 0 while pc < nTokens { if "!!*0 = !!*1;".compare(f, id: 1, beginning: pc) { // 単純代入 // このブロックで実行して、その結果を変数に書き込む } ...
この最後の変更は、単にわたしは癖で大事な部分をできるだけ左に寄せて書いたほうが読みやすく感じるので変えただけのことです。引数の並び順を考えると、公式処理系の書き方のほうが意味が取りやすく自然に読めます。
ちょっと脱線しますが、気分的には"!!*0 = !!*1;".compare(beginning: pc)のような感じで書きたかったのです。
しかしこれをそのまま実装してしまうと高速化の観点からは悪手です。公式処理系の書き方で実装したときとの速度差が生じないように実測しながらあれこれ試しているうちに、結局、処理本体の記述は公式処理系とほぼ同じである、いまの実装に落ち着いたのでした。
さて、いま「大事な部分を」と書きましたけれど、これはフレーズのことですね。フレーズは構文を表した文字列でした。上で例示したコードでは代入を表す"!!*0 = !!*1;"という文字列をフレーズに指定しています。「!!*#」は任意の1トークンにマッチするワイルドカードです。
あとのバージョン(HL-7)で任意の式にマッチするワイルドカードを追加すると、"if (!!**0) {""や"for (!!***0; !!***1; !!***2) {"などの構文を表す文字列もフレーズに指定できるようになります。
フレーズを使う前に比べるとずいぶん構文が読みやすくなりますね。
実際に自作言語の仕様を決めるときのことを想像してみると、書き心地を試しながら、よりよい記法はないだろうか? と納得するまでフレーズをいじり、試行錯誤を繰り返すことになるでしょう。
このように試行錯誤を繰り返すことを前提とすると、フレーズを読むこと・書き換えることにかかるコストを低減するほど、そのぶん言語を改造する生産性を高めることに貢献しそうです。
だから、phrCmp関数は高速化の観点から大事な関数というだけではなく、ユーザ(プログラマ)が言語を改造する際のインターフェースを提供しているという意味でも大事な関数だと思うのです。
HL-6 「もっと高速化(がんばった!)」
http://essen.osask.jp/?a21_txt01_6
HL-6では、高速化のためにソースコードを内部コードへコンパイルしてVMの上で実行する方式を採用します。
6章の冒頭には、JITコンパイラやインラインアセンブラを使わない範囲での最速を目指すと書かれています。そして、あわせて次のように書かれています。
基本方針としては、tc[]をphrCmp()で一致しているかどうか調べながら実行するのはやめて、もっとシンプルで高速に実行できそうなデータ列に変換し(内部コードへのコンパイル)、その後そのデータ列だけを見て高速に実行します。
また、言語自作入門の冒頭に書かれている目的別ガイドには次のように書かれています。
実行速度を高める工夫に興味があれば、HL-5やHL-6まで読めばいいです。HL-6では内部に簡単なVMを作ります。徐々にコンパイラっぽくなってきます。
なにやら処理系がやることが増えてきました。いちど整理しておきます。
わたしはHL-5の感想文の冒頭で、HL-5までのはりぼて言語の公式処理系がやっていることの流れを次のように図示しました。
ソースコードを入力として受け取る -> 字句解析をする -> 構文解析をしながら実行する
この図にHL-6で実装する内容を描き加えると次のようになります。
ソースコードを入力として受け取る -> 字句解析をする -> 構文解析をしながら内部コードへコンパイルする -> VMの上で内部コードを読み取って実行する
「構文解析をしながら実行する」が「構文解析をしながら内部コードへコンパイルする -> VMの上で内部コードを読み取って実行する」に変わっていますね。
JITコンパイラ編とのつながり
HL-6には、C言語による実装をしたときに印象に残った思い出があるんです。
若干JITコンパイラ編のネタバレのような感じになってしまうのですが、これはぜひ書いておきたいと思いました。
putIc関数は、引数で渡された内容の内部コードを変数icに書き込みます。この書き込みは書き込み用のポインタicqを介しておこないます。
公式処理系では関数本体はこうなっています。
void putIc(int op, IntP p1, IntP p2, IntP p3, IntP p4) { icq[0] = (IntP) op; icq[1] = p1; icq[2] = p2; icq[3] = p3; icq[4] = p4; icq += 5; }
第一引数は命令の種類を表す列挙型で、第二引数以降は命令を実行するのに必要なオペランドの格納先アドレスです。
たとえば、このputIc関数を使って代入のための内部コードを書き込む呼び出しはこう書きます。
putIc(OpCpy, &var[tc[wpc[0]]], &var[tc[wpc[1]]], 0, 0);
この代入のための内部コードを書き込む呼び出しを、JITコンパイラ編で機械語を書き込むように変更するとこうなります。
putIcX86("8b_%1m0; 89_%0m0;", &var[tc[wpc[0]]], &var[tc[wpc[1]]], 0, 0);
むむっ! ほとんど同じです。
なんと、HL-6の処理系が何をやっているかの理解が、JITコンパイラ編の処理系の理解につながるように実装が工夫されているのです。
わたしは機械語にひるみながらJITコンパイラ編を読みはじめましたが、これまでやってきたこととのつながりに気づくと一気に気持ちが軽くなったのでした。
SwiftでHL-6を実装する
さて、実はわたしは今回のチャレンジでは、SwiftでHL-6を実装しきれるか、また実装できたとしても高速化に成功するかを心配していました。
はりぼて言語の公式処理系は、原則的にポインタをやむをえないときに使い、ポインタに対する加算や減算はできるだけおこなわない方針のもとに実装されています。
ただしHL-6は高速かつ簡潔に書くために例外的にポインタを多用しています。その部分を使いだして間もないSwiftで実装しきれるかが不安だったのです。
しかしSwiftのポインタを使うと、わりと楽に公式処理系と似たように書くことができたのでラッキーでした。
ポインタを多用する部分はわりと楽に書けたのでしたが、しばらくは見えないコストを抑える方法がわからず、それに阻まれてなかなか思うようなタイムを出せずに苦しみました。しかし-whole-module-optimizationオプションを見つけました。
このオプションを指定してコンパイルした処理系で、HL-3のサンプルコードの1億回ループを実行して速度を測定した結果がこちらです。
| Swiftによる実装(swiftc -O -whole-module-optimization) |
|---|
| 0.624[sec] |
| C言語による実装(gcc -O3) |
|---|
| 0.284[sec] |
比較のためにあわせてC言語による実装の実行速度も載せてみました。C言語による実装との速度差がこの程度であればひとまず成功と考えます。
画面に「0.624[sec] 」と表示された瞬間は、ほんとうに安心しました。
HL-6a 「さらに高速化!(これをやるかどうかは好みが分かれるかも)」
http://essen.osask.jp/?a21_txt01_6a
使用頻度が高い命令についてはCISC的な内部命令を作ると速くなるようです。
実際に、LOOP命令のような専用命令を追加すると1億回ループがさらに速くなりました。
| Swiftによる実装(swiftc -O -whole-module-optimization) |
|---|
| 0.506[sec] |
| C言語による実装(gcc -O3) |
|---|
| 0.256[sec] |
はりぼて言語のVMは、次に実行する命令のアドレスを指すicpの値を書き換えながら内部コードを実行します。
この「icpに加算してcontinueしてそしてswitchするというのが、結構なコストになっている[…]だから2つの命令をくっつけて1つにするだけで、それが1回減らせて、かなりの高速化に」なるということらしいです。
これは覚えておきたいですね。
おわりに
はじめは49行だったはりぼて言語の処理系が、手を動かしながら読むうちに徐々にパワーアップしていくのを見ていると、これまでは手が届かないと思っていた処理系の世界に少しずつ足を踏み入れている実感が湧いて、とてもわくわくしたものです。
はりぼて言語の処理系は徐々にパワーアップしていくので、ある時点では全容が見えません。全容が見えないがゆえに、ああだろうかこうだろうかと考えます。
もしこの、ああだろうかこうだろうか、をリアルタイムに誰かと雑談できていたらたのしかったんだろうなぁ、と思いました。
だからわたしは、この感想文の冒頭に次のように書いたのです。
いままさに言語自作入門を読んでいる人たち・はりぼて言語の処理系を実装している人たちと、わいわいにぎやかに雑談しているような気持ちで書いてみようと思います。
でも感想文を書き終えたいまは、もしかするとこの感想文を書くこと自体が「過去のわたし」と「いまのわたし」の雑談だったのかもしれないな、という気がしています。
最後になりましたが、はりぼて言語の処理系の実装と説明を公開いただいていることにあらためて感謝いたします。
このテキストは言語自作したい人向けに書いているものですが、最も読ませたい相手は19年前の私自身だなと今は思います。
— 川合秀実 (@hkawai3) 2021年4月22日
19年前の私は12.5KB程度のプログラムにそんなことが可能だなんて想像もできませんでした。私も一応成長したようです。・・・さらに19年後には、もっとできるようになりたいです。